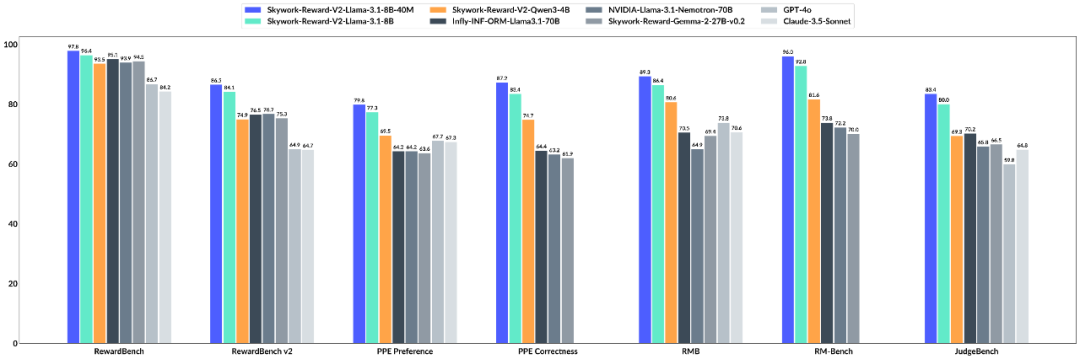
 大语言模型(LLM)以其强大的发电能力而闻名,但是如何使其“听话”是一门深刻的科学。基于人类反馈(RLHF)的强化学习用于解决此问题。薪酬模型(RM)在法官中起着重要的作用。它特别负责写下LLM产生的内容,并告诉模型什么是好是坏的。因此,奖励模型对于大型模型的功能极为重要。它必须能够准确地判断,并且足够涵盖多个知识领域。它还具有灵活的试用功能,管理多个条目,并且足够扩展。 7月4日,Kunlun Wanwei的国家技术公司推出了Skywork-Reward-V2系列新一代奖励模型。 Skywork-Reward-V2系列包括八种不同的奖励模型基本型号和不同的尺寸,参数尺寸从6亿到80亿。他将第一名分类为常规奖励模型的七个资格列表。 Skywork-Reward-V2系列模型在常规参考点上的结果。同时,一组模型展示了广泛的适用性,在多个功能维度中效果很好,包括通用对齐,目标的校正,安全性,样式偏见和对最佳扩展的电阻N。技术报告:https://arxiv.org/abs/2507.01352 huggingface地址:https:// huggingfaces https://github.com/skyworkai/skyworkai/skyworkai/skywork-work-workwork-work-word-word-ward-v2。在过去的九个月中,这项工作已被广泛用于开源社区的研究和实践,现在正在采用。平台面的累积下载超过了750,000次,几种Avant -Garde模型通过奖励等享有声望的评论帮助他们取得了成果。这次,Kunlun Wanwei的开源奖励模型可以吸引更多的关注者离子。为数十亿人创建偏好数据,以不断遵守大型模型的生产并不是一项简单的任务。由于现实世界的复杂性和多样性,奖励模型往往仅作为理想的偏好而作为不完整的代理可用。通过优化奖励模型,这种失败会导致最佳问题。该模型可以克服奖励模型中的偏差,并偏离实际人类偏好。从实际结果来看,最先进的开源奖励模型不能与大多数评估参考点规定的效果良好。他们通常无法有效地捕获人类偏好的详细且复杂的特性,尤其是当他们面对多维和多级反馈时。他们的能力特别有限。此外,尽管许多奖励模型在特定的参考任务中倾向于很好地发挥作用,但要继续进行新任务和新方案,这表明明显的“调整后”。虽然resEarch试图通过优化客观特征,改善模型架构并改善最近出现的生成奖励模型来提高性能,总体效果仍然非常有限。左图:比较奖励银行中31个上开源奖励模型的特征。正确的图像:得分相关性:我们可以看到许多模型在奖励库中的性能提高了,但是其他参考点的资格是“卡住”。同时,DeepSeek-R1代表的模型或OpenAI和模型促进了“具有可验证奖励的强化学习”(RLVR)的开发,确定生成模型的产生的结果是否通过人物的一致性满足了预先建立的需求,即系统单位的测试或多个复杂规则的一致性的机制。在某些具有控制和稳定性的情况下,这种方法很昂贵,它们本质上很难终极捕获复杂而细致的人类偏好,因此在优化开放且高度主观的任务时存在明显的局限性。在这方面,Kunlun Wanwei试图在两个主要方向上解决该问题:数据构建和基本模型。首先,他们构建了有史以来最大的首选混合数据集,Skywork-synpref-40m,其中包含4000万对首选样品。共同创新是在“人类机器协作,两阶段迭代”的数据选择管中发现的。两个阶段优先数据分类过程。如图所示,此过程分为两个主要阶段。第一阶段,是人类指导的高质量偏好的小结构。在此阶段,研究人员创建了一种可以在RLHF中存在的双轨机制:“缺乏高质量数据→弱模型→低生成数据质量”。一方面,他们使用有限的手动精度打破了第一个瓶颈,另一方面,他们使用模型的独特特征实现了质量进步。具体而言,大型人工模型分别标记了“金”和“银”的优先数据,而用银数据进行了奖励模型,这些奖励模型与金数据进行了比较以评估其不便。然后,系统选择一个类似配置的样本,该样本在当前的奖励模型中无法很好地工作,在M的以下迭代中重现R和R训练,此过程已重复多次。第二阶段是扩展大量,自动和优先级数据。在此阶段,手动参与审核是不再可能的,在培训中完成的奖励模型会吸引潜在客户并执行数据的二次过滤。在这一点上,系统将第一阶段的奖励模型与“金”奖励模型相结合,尤其是通过人类数据训练的“金”奖励模型,以通过一致性机制指导数据选择。这个st年龄不需要手动监督,这使您可以攀登数百万个首选数据对。从有效性的角度来看,这过程将手动验证的质量保证与基于人类偏好的注释相结合,以实现大型语言模型(LLM)并实现高可扩展性。最终,最初的4000万样本“变薄”是2600万个选定的数据,不仅显着降低了手动标记负载,而且还有助于平衡规模和质量。分支体积限制:参数根据数十个时间而有所不同,可以用作由人类计算机组合数据训练的Sky Work-V2奖励模型,从而实现了超出预期的功能。与去年9月推出的SkyWork-Reward相比,工程师根据Skywork-Reward-V2 Qwen3系列培训了八种奖励模型,并呼叫3,这导致了参数量表的更大覆盖范围。在下表中,我们可以看到Skywork-Reward-V2在奖励参考点上以V1/V2奖励银行,PPE偏好的更正以及对常规奖励模型的评估参考点(例如RMB,RM Bench and JudgeBench)建立了最佳记录。 SOTA结果的背后,可以提取以下重要发现:首先,数据质量的改进和丰度可以显着补偿参数量表的限制,这使得奖励模型可以在小型专家模型中用于特定任务。例如,在V2奖励中,评估奖励模型的参考,Skywork-Reward-V2显示出出色的功能,并按照说明进行精确。即使是最小的Skywork-V2-QWEN3-0.6B SKYWORK也因一般差距而大大减少了Skywork-Reward-Gemma-2-27b-V0.2,这是Geneprevious评估的最强模型,并且参数量表的总差异为45次。超越了平均表演Skywork-Reward-V2-Qwen3-1.7b的CE与当前SOTA-INF-INF-INM-LLAMA 3.1-70B开源奖励模型的平均性能没有显着差异。除强大的封闭代码模型(Claude-3.7-sonnet)和最新一代奖励模型外,所有传统参考点都超出了最大的Skywork-Reward-v2-llama-3.1-8B和Skywork-reward-v2-v2-llamamama-3.1-8B-4.8B-40M当前奖励。 V2奖励银行的参考结果。执行分数的提高意味着数据工程策略的作用变得越来越重要,这意味着高质量的目标和培训数据可以支持“小?蔬菜”。 AdeMás,基于数据的结构+的优化足以与简单的桩参数竞争,也值得考虑详尽的模型训练范式。其次,随着人类价值的结构建模能力得到了增强,奖励模型已开始从“弱管理者SCOR”转移到在“普遍价值的强大建模者”中。在评估精确目标(法官)的参考时,Skywork-Reward-V2的一般性能比某些关注推理和编程的封闭代码模型要弱,例如OpenAI系列,但比所有其他知识范围的级别都更好。 O3-Mini(高)和Skywork-Reward-v2-3.1-8b与顶级LLM-A-A-A模型 - 作为GPT-4O模型的绩效比较,在Judgent Bench的参考和推理模型中(O1系列),在八个模型中,八个模型 - 功能(最佳-N)在实用程序中和无害指标中,最高领导能力超过了先前的SOTA GPT-4O模型下面的五个困难PPE精确任务的bon曲线,我们可以看到Skywork Rewards-V2具有连续的正伸缩性,所有这些都达到了CABE。其他先进的能力评估,例如偏见抵抗测试(RM银行),对复杂指导的理解,可靠性判断(奖励基础V2)和SkyWork-RecompenSa-V2表现出强大的概括和实用性能力。 RM银行专注于评估抵制样式偏见的模型。在RM银行,Skywork-Reward-V2将获得Sota。最后,在后部多次迭代训练中,最好的检测和过滤优先确定优先数据的优先级数据,并有效地奖励模型的一般性能,再次确认了Skywork SimpleV数据集的规模和质量好处,并且还展示了“较少精致”范式的魔力。为了验证这一点,工程师试图尝试以前的1600万个数据子集的版本,但是结果他们使用(然后)使用1.8%(约290,000)(约290,000)的高质量数据来训练超过当前SOTA 70B奖励模型的8B标度模型。图的左侧显示了整个数据过滤过程中奖励模型得分的变化趋势(原始数据,过滤数据,过滤数据 +)包括三个阶段的Peaire PairsCorrection Rentence。该图的右侧显示了Skywork-Reward-v2-3.1-8b奖励模型的早期版本的平均得分(即,在最后的训练回合中,Call-3.1-8b call-3.1-8b call-3.1-8b)在最终训练回合中的平均得分(即Call-3.1-8B-BTRM)。在奖励模型的能力限制中,基于未来的奖励范围,即将在未来的智能范围内限制了奖励的能力。最强大的仓库级别代码下的32B开源型号“矩阵游戏”。行业10B +太空智能大型模型。 “ SkyWork-R1V”多模式链的推理模型:在视觉模式下成功过渡的强大文本推理能力。视频生成系列模型:Skyreels-v1的第一个无限电影生成模型和今年4月推出的迭代版本:Skyreels-V2。数学代码推理模型“ SkyWork-OR1”:它以相同的参数量表实现了行业中的领先推论性能,进一步打破了对大型模型的逻辑理解和复制。解决其他任务时的技能瓶颈。这组开源来源不可避免地会加速在大规模模型领域的技术迭代速度。
大语言模型(LLM)以其强大的发电能力而闻名,但是如何使其“听话”是一门深刻的科学。基于人类反馈(RLHF)的强化学习用于解决此问题。薪酬模型(RM)在法官中起着重要的作用。它特别负责写下LLM产生的内容,并告诉模型什么是好是坏的。因此,奖励模型对于大型模型的功能极为重要。它必须能够准确地判断,并且足够涵盖多个知识领域。它还具有灵活的试用功能,管理多个条目,并且足够扩展。 7月4日,Kunlun Wanwei的国家技术公司推出了Skywork-Reward-V2系列新一代奖励模型。 Skywork-Reward-V2系列包括八种不同的奖励模型基本型号和不同的尺寸,参数尺寸从6亿到80亿。他将第一名分类为常规奖励模型的七个资格列表。 Skywork-Reward-V2系列模型在常规参考点上的结果。同时,一组模型展示了广泛的适用性,在多个功能维度中效果很好,包括通用对齐,目标的校正,安全性,样式偏见和对最佳扩展的电阻N。技术报告:https://arxiv.org/abs/2507.01352 huggingface地址:https:// huggingfaces https://github.com/skyworkai/skyworkai/skyworkai/skywork-work-workwork-work-word-word-ward-v2。在过去的九个月中,这项工作已被广泛用于开源社区的研究和实践,现在正在采用。平台面的累积下载超过了750,000次,几种Avant -Garde模型通过奖励等享有声望的评论帮助他们取得了成果。这次,Kunlun Wanwei的开源奖励模型可以吸引更多的关注者离子。为数十亿人创建偏好数据,以不断遵守大型模型的生产并不是一项简单的任务。由于现实世界的复杂性和多样性,奖励模型往往仅作为理想的偏好而作为不完整的代理可用。通过优化奖励模型,这种失败会导致最佳问题。该模型可以克服奖励模型中的偏差,并偏离实际人类偏好。从实际结果来看,最先进的开源奖励模型不能与大多数评估参考点规定的效果良好。他们通常无法有效地捕获人类偏好的详细且复杂的特性,尤其是当他们面对多维和多级反馈时。他们的能力特别有限。此外,尽管许多奖励模型在特定的参考任务中倾向于很好地发挥作用,但要继续进行新任务和新方案,这表明明显的“调整后”。虽然resEarch试图通过优化客观特征,改善模型架构并改善最近出现的生成奖励模型来提高性能,总体效果仍然非常有限。左图:比较奖励银行中31个上开源奖励模型的特征。正确的图像:得分相关性:我们可以看到许多模型在奖励库中的性能提高了,但是其他参考点的资格是“卡住”。同时,DeepSeek-R1代表的模型或OpenAI和模型促进了“具有可验证奖励的强化学习”(RLVR)的开发,确定生成模型的产生的结果是否通过人物的一致性满足了预先建立的需求,即系统单位的测试或多个复杂规则的一致性的机制。在某些具有控制和稳定性的情况下,这种方法很昂贵,它们本质上很难终极捕获复杂而细致的人类偏好,因此在优化开放且高度主观的任务时存在明显的局限性。在这方面,Kunlun Wanwei试图在两个主要方向上解决该问题:数据构建和基本模型。首先,他们构建了有史以来最大的首选混合数据集,Skywork-synpref-40m,其中包含4000万对首选样品。共同创新是在“人类机器协作,两阶段迭代”的数据选择管中发现的。两个阶段优先数据分类过程。如图所示,此过程分为两个主要阶段。第一阶段,是人类指导的高质量偏好的小结构。在此阶段,研究人员创建了一种可以在RLHF中存在的双轨机制:“缺乏高质量数据→弱模型→低生成数据质量”。一方面,他们使用有限的手动精度打破了第一个瓶颈,另一方面,他们使用模型的独特特征实现了质量进步。具体而言,大型人工模型分别标记了“金”和“银”的优先数据,而用银数据进行了奖励模型,这些奖励模型与金数据进行了比较以评估其不便。然后,系统选择一个类似配置的样本,该样本在当前的奖励模型中无法很好地工作,在M的以下迭代中重现R和R训练,此过程已重复多次。第二阶段是扩展大量,自动和优先级数据。在此阶段,手动参与审核是不再可能的,在培训中完成的奖励模型会吸引潜在客户并执行数据的二次过滤。在这一点上,系统将第一阶段的奖励模型与“金”奖励模型相结合,尤其是通过人类数据训练的“金”奖励模型,以通过一致性机制指导数据选择。这个st年龄不需要手动监督,这使您可以攀登数百万个首选数据对。从有效性的角度来看,这过程将手动验证的质量保证与基于人类偏好的注释相结合,以实现大型语言模型(LLM)并实现高可扩展性。最终,最初的4000万样本“变薄”是2600万个选定的数据,不仅显着降低了手动标记负载,而且还有助于平衡规模和质量。分支体积限制:参数根据数十个时间而有所不同,可以用作由人类计算机组合数据训练的Sky Work-V2奖励模型,从而实现了超出预期的功能。与去年9月推出的SkyWork-Reward相比,工程师根据Skywork-Reward-V2 Qwen3系列培训了八种奖励模型,并呼叫3,这导致了参数量表的更大覆盖范围。在下表中,我们可以看到Skywork-Reward-V2在奖励参考点上以V1/V2奖励银行,PPE偏好的更正以及对常规奖励模型的评估参考点(例如RMB,RM Bench and JudgeBench)建立了最佳记录。 SOTA结果的背后,可以提取以下重要发现:首先,数据质量的改进和丰度可以显着补偿参数量表的限制,这使得奖励模型可以在小型专家模型中用于特定任务。例如,在V2奖励中,评估奖励模型的参考,Skywork-Reward-V2显示出出色的功能,并按照说明进行精确。即使是最小的Skywork-V2-QWEN3-0.6B SKYWORK也因一般差距而大大减少了Skywork-Reward-Gemma-2-27b-V0.2,这是Geneprevious评估的最强模型,并且参数量表的总差异为45次。超越了平均表演Skywork-Reward-V2-Qwen3-1.7b的CE与当前SOTA-INF-INF-INM-LLAMA 3.1-70B开源奖励模型的平均性能没有显着差异。除强大的封闭代码模型(Claude-3.7-sonnet)和最新一代奖励模型外,所有传统参考点都超出了最大的Skywork-Reward-v2-llama-3.1-8B和Skywork-reward-v2-v2-llamamama-3.1-8B-4.8B-40M当前奖励。 V2奖励银行的参考结果。执行分数的提高意味着数据工程策略的作用变得越来越重要,这意味着高质量的目标和培训数据可以支持“小?蔬菜”。 AdeMás,基于数据的结构+的优化足以与简单的桩参数竞争,也值得考虑详尽的模型训练范式。其次,随着人类价值的结构建模能力得到了增强,奖励模型已开始从“弱管理者SCOR”转移到在“普遍价值的强大建模者”中。在评估精确目标(法官)的参考时,Skywork-Reward-V2的一般性能比某些关注推理和编程的封闭代码模型要弱,例如OpenAI系列,但比所有其他知识范围的级别都更好。 O3-Mini(高)和Skywork-Reward-v2-3.1-8b与顶级LLM-A-A-A模型 - 作为GPT-4O模型的绩效比较,在Judgent Bench的参考和推理模型中(O1系列),在八个模型中,八个模型 - 功能(最佳-N)在实用程序中和无害指标中,最高领导能力超过了先前的SOTA GPT-4O模型下面的五个困难PPE精确任务的bon曲线,我们可以看到Skywork Rewards-V2具有连续的正伸缩性,所有这些都达到了CABE。其他先进的能力评估,例如偏见抵抗测试(RM银行),对复杂指导的理解,可靠性判断(奖励基础V2)和SkyWork-RecompenSa-V2表现出强大的概括和实用性能力。 RM银行专注于评估抵制样式偏见的模型。在RM银行,Skywork-Reward-V2将获得Sota。最后,在后部多次迭代训练中,最好的检测和过滤优先确定优先数据的优先级数据,并有效地奖励模型的一般性能,再次确认了Skywork SimpleV数据集的规模和质量好处,并且还展示了“较少精致”范式的魔力。为了验证这一点,工程师试图尝试以前的1600万个数据子集的版本,但是结果他们使用(然后)使用1.8%(约290,000)(约290,000)的高质量数据来训练超过当前SOTA 70B奖励模型的8B标度模型。图的左侧显示了整个数据过滤过程中奖励模型得分的变化趋势(原始数据,过滤数据,过滤数据 +)包括三个阶段的Peaire PairsCorrection Rentence。该图的右侧显示了Skywork-Reward-v2-3.1-8b奖励模型的早期版本的平均得分(即,在最后的训练回合中,Call-3.1-8b call-3.1-8b call-3.1-8b)在最终训练回合中的平均得分(即Call-3.1-8B-BTRM)。在奖励模型的能力限制中,基于未来的奖励范围,即将在未来的智能范围内限制了奖励的能力。最强大的仓库级别代码下的32B开源型号“矩阵游戏”。行业10B +太空智能大型模型。 “ SkyWork-R1V”多模式链的推理模型:在视觉模式下成功过渡的强大文本推理能力。视频生成系列模型:Skyreels-v1的第一个无限电影生成模型和今年4月推出的迭代版本:Skyreels-V2。数学代码推理模型“ SkyWork-OR1”:它以相同的参数量表实现了行业中的领先推论性能,进一步打破了对大型模型的逻辑理解和复制。解决其他任务时的技能瓶颈。这组开源来源不可避免地会加速在大规模模型领域的技术迭代速度。



 推荐文章
推荐文章









以其强大的发电能力而闻名,但是如何使其“听话”是一门深刻的科学。基于人类评论的强大化学反应')){kind=link}
以其强大的发电能力而闻名,但是如何使其“听话”是一门深刻的科学。基于人类评论的强大化学反应')){kind=link}
以其强大的发电能力而闻名,但是如何使其“听话”是一门深刻的科学。基于人类评论的强大化学反应')){kind=link}
){kind=link}